26/11/2020
ALESSANDRO DI ANTONIOPrincipal technical consultant
|
In questo articolo vogliamo analizzare l’architettura e le funzionalità del nuovo servizio Microsoft Azure Synapse, confrontandolo con lo storico Database Sql Server. Sulla base della nostra esperienza, evidenzieremo le differenti modalità di gestione dei dati che le due tecnologie richiedono in un contesto di Enterprise Data Warehouse.
Synapse
Annunciato a novembre 2019, Azure Synapse è l’evoluzione di Azure SQL Data Warehouse. Microsoft lo definisce come uno strumento che permette di unire i big data all’enterprise data warehouse (EDWH), portando i vantaggi dei due mondi in un unico servizio cloud ad alte prestazioni e facilmente scalabile. Il passaggio a questa tecnologia però, rispetto all’EDWH tradizionale basato su SQL Server, prevede un diverso approccio alla gestione dei dati e un cambio di mentalità nei confronti dell’ingestion classica dei dati.
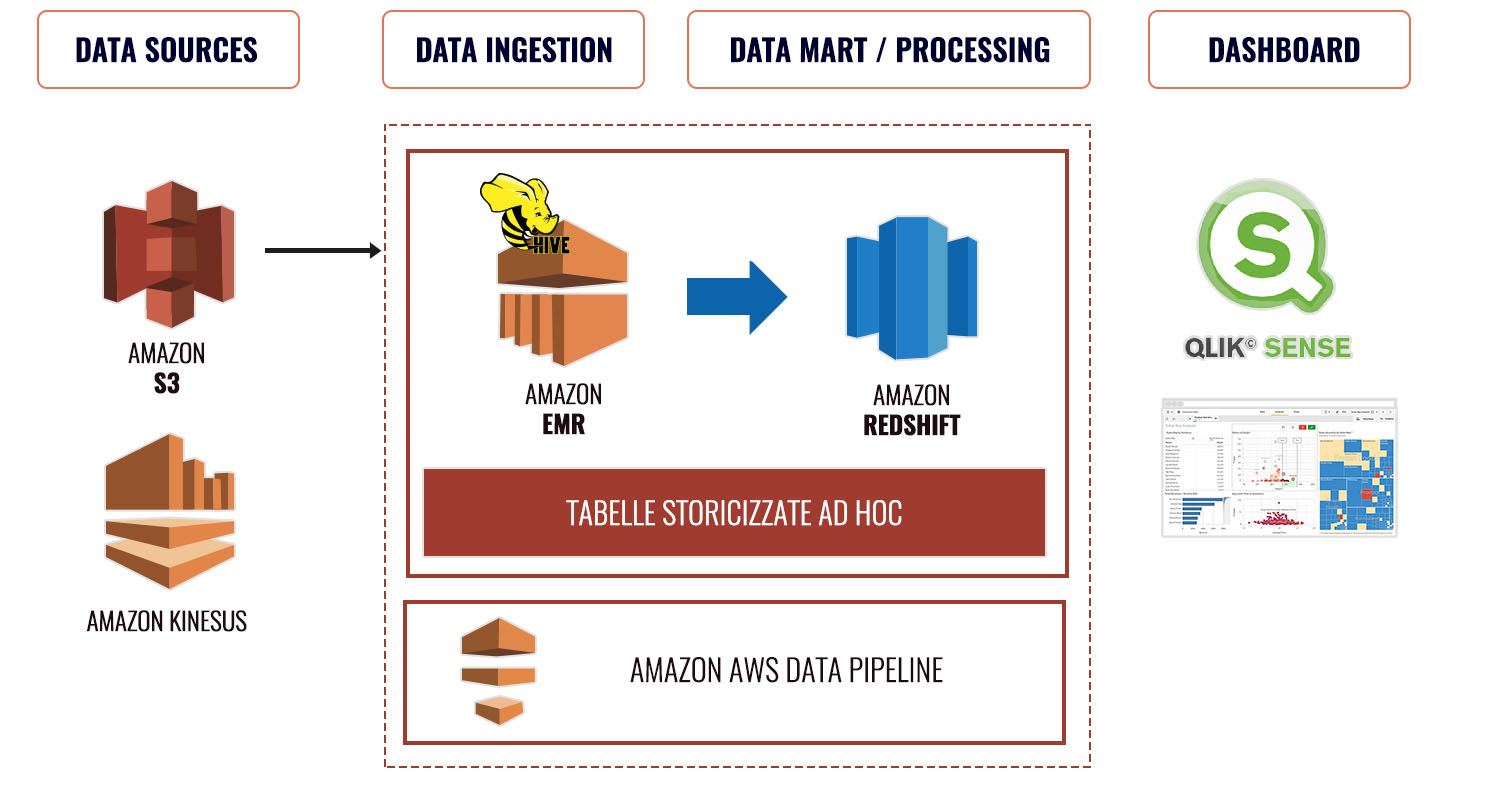
Cominciamo delineando brevemente le caratteristiche di Azure Synapse e come esso si differenzi profondamente da SQL Server: Synapse si basa su un motore di Massively Parallel Processing (MPP), la cui architettura permette di scalare l’esecuzione delle query su più nodi. La computazione è completamente disaccoppiata dall’archiviazione dei dati (basata su Azure Storage), consente quindi di mettere in pausa il servizio di calcolo, fermando i suoi consumi, ma preservando i dati archiviati.
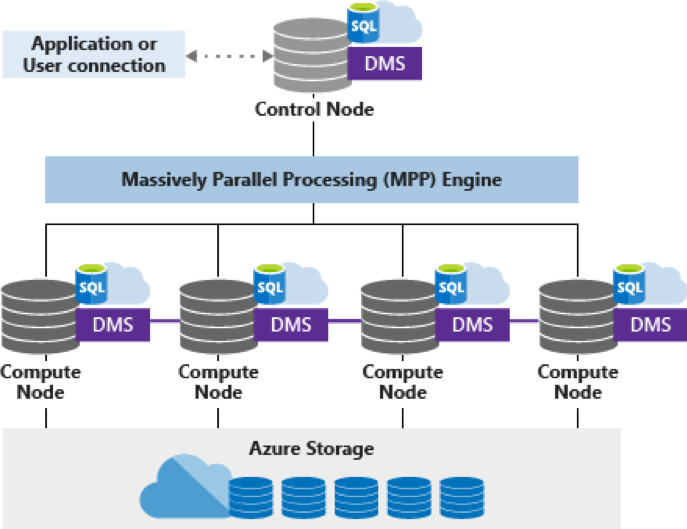
L’architettura MPP si compone quindi di diverse componenti:
- Nodo di controllo, che riceve le query T-SQL e le distribuisce sui nodi computazionali;
- Nodi computazionali, che eseguono in parallelo i vari processi prima di restituire i risultati al nodo di controllo;
- Data Movement Service, che trasporta i dati tra i nodi computazionali per la corretta esecuzione delle query;
- Azure Storage per l’archiviazione delle tabelle.
Le tabelle sono partizionate per l’ottimizzazione delle prestazioni, la scelta del metodo di partizionamento viene fatta in fase di creazione della tabella e può essere di tre tipi:
- Hash, dove la tabella viene distribuita utilizzando una funziona di hash calcolata in base al valore di una o più colonne della tabella – questo metodo permette migliori performance delle query;
- Round-robin, dove il dato viene distribuito equamente sulle varie distribuzioni – metodo ideale per le tabelle di staging;
- Replica, dove la tabella è replicata interamente sulle varie distribuzioni – questo metodo è consigliabile per una maggiore velocità di accesso a tabelle di dimensioni ridotte.
Sql Server
L’architettura di Synapse è molto differente da quella di SQL Server: i dati ed il motore del database di SQL Server risiedono sullo stesso server e quest’ultimo si occupa di eseguire le query utilizzando la potenza computazionale a disposizione del servizio di database. Il modello computazionale non è quindi parallelo, nel senso che le query non vengono eseguite su più macchine in contemporanea e le tabelle non sono (nativamente) ripartite su distribuzioni e non vengono interrogate separatamente; queste ultime sono archiviate utilizzando algoritmi differenti rispetto a quelli di Synapse, principalmente si distinguono tabelle heap, clustered e colonnari.
ETL vs ELT
Questa differenza nelle modalità di archiviazione e elaborazione dei dati comporta la necessità di affrontare l’acquisizione dei dati su Synapse utilizzando un paradigma diverso da quello dell’ETL classico, l’ELT. L’ELT prevede di trasformare i dati dopo averli caricati sull’ambiente di destinazione, avvantaggiandosi delle prestazioni offerte dal motore del database nell’integrare, calcolare ed aggregare le informazioni.
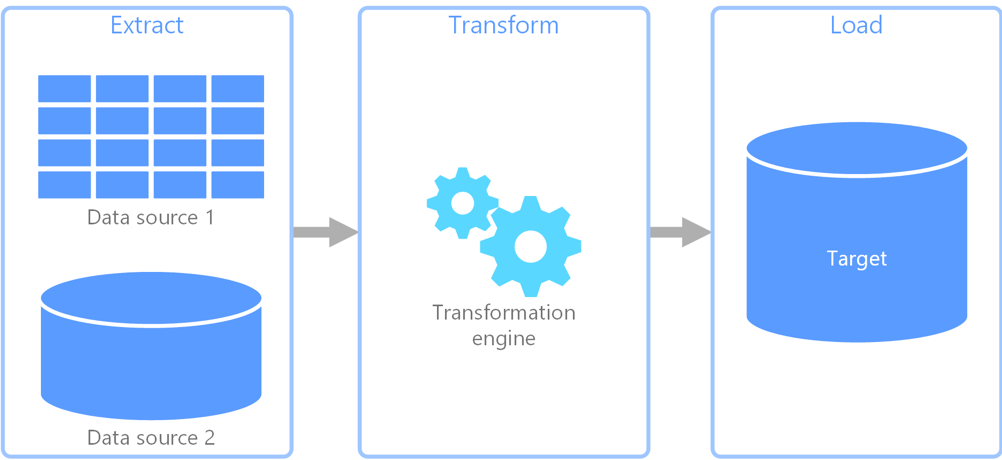
Azure Synapse rappresenta un ambiente ideale per l’utilizzo di una logica di tipo ELT grazie all’archiviazione diretta sul file system Azure Storage e alle elevate prestazioni nel trattamento di grandi volumi di dati. Queste caratteristiche consentono di importare nello storage Azure i dati dalle fonti sorgenti e utilizzare l’architettura MPP per caricare i dati direttamente dallo storage all’interno delle tabelle di staging, combinando la semplicità di scrittura e lettura da un file system con i vantaggi della definizione di uno schema per le tabelle durante l’importazione.
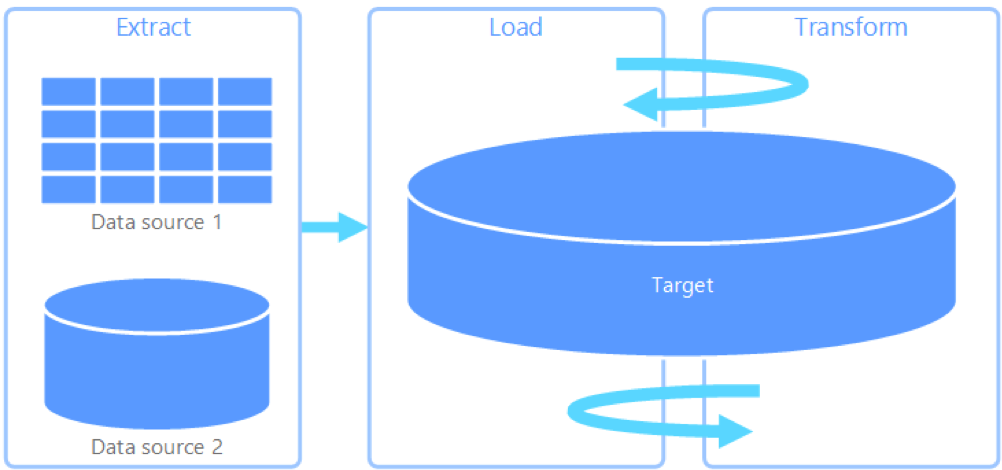
Questo tipo di scenario però, unito alle limitazioni rispetto ad alcuni costrutti SQL disponibili su SQL Server, rende necessario ripensare la trasformazione dei dati, le modalità di gestione dello storico e più in generale il disegno della base dati EDWH su Synapse.
Se infatti la velocità nell’importazione dei dati su Synapse è molto elevata, una volta create le tabelle di staging sul DataWarehouse, alcuni comandi SQL non sono disponibili; in particolare non è disponibile il comando MERGE (o un comando analogo in grado di effettuare UPSERT) e ci sono limitazioni nell’uso delle JOIN esplicite nelle clausole FROM nei comandi di UPDATE e DELETE. Questo ha certamente un impatto sul modo di caricare i dati in un EDWH.
Su SQL Server, una volta caricati i dati sorgenti nelle tabelle di staging, questi vengono portati nelle tabelle finali tramite operazioni di JOIN, vengono effettuati eventuali controlli di coerenza dei dati e applicate le opportune politiche per la gestione delle variazioni e della storicizzazione dei dati.
Per effettuare queste operazioni in Synapse, ci sono diversi modi. Una prima soluzione “di forza bruta” è quella di sfruttare le enormi potenzialità dello strumento. Se le condizioni lo consentono (per dimensioni dei dati e velocità di estrazione dall’origine, oppure per la preponderanza di dati nuovi o modificati sul totale) possiamo importare per intero la tabella ad ogni caricamento, creando delle fotografie complete della base dati. Questa soluzione è funzionale per i casi in cui la nuova versione della tabella sostituisce completamente la precedente, oppure se il dato storico non è oggetto di frequenti query.
Questa prima soluzione fa leva sulle maggiori capacità di elaborazione ed archiviazione del dato di Synapse rispetto a SQL Server e sottende un modo di vedere l’EDWH diverso da quello classico: prima si importa il dato e si demanda alle estrazioni l’applicazione delle logiche.
Una seconda soluzione è invece quella di implementare la parte d’identificazione delle variazioni dei dati attraverso l’uso dei comandi disponibili in Synapse. Questo si ottiene facendo ricorso al comando CREATE TABLE AS SELECT (CTAS): questo comando consente di creare delle tabelle leggendo direttamente i dati da un’altra tabella o da un file. Utilizzando il CTAS per creare delle tabelle temporanee di appoggio, si possono materializzare i passaggi necessari a eseguire MERGE o UPDATE non supportate dalla sintassi di Synapse. Per esempio, è possibile materializzare il risultato di una JOIN necessaria per un UPDATE, per poi aggiornare la tabella di destinazione mediante una JOIN implicita con la tabella temporanea.
Ma non è finita qui, tra le funzionalità in preview sono presenti alcune possibilità per venire incontro a queste necessità. Una di queste possibilità prevede l’utilizzo di Azure Data Factory, lo strumento Azure per l’orchestrazione dei dati. All’interno di una pipeline creata utilizzando Azure Data Factory è possibile utilizzare Synapse come destinazione e impostare il metodo di UPDATE che consente di gestire gli UPSERT.
Un’altra tecnologia in preview è Delta Lake, layer che consente di gestire le transazioni ACID tramite Spark. L’interazione con Synapse avviene tramite Azure Databricks, che consente di spostare i dati da Azure Storage verso Synapse e di trasformarli usufruendo dei vantaggi della computazione parallela forniti da Spark. È doveroso sottolineare che l’utilizzo congiunto di Spark e Synapse va oltre l’alimentazione del layer dati, apre infatti scenari estremamente interessanti in termini di analisi avanzate e modelli predittivi.
Conclusioni
Abbiamo visto come si differenziano tra di loro SQL Server e Azure Synapse e dei differenti approcci da utilizzare per la creazione di un EDWH utilizzando quest’ultima tecnologia. Anche se rispetto al classico approccio su SQL Server, è necessario un cambio di paradigma, i vantaggi in fatto di scalabilità, parallelismo, gestione dei big data e integrazione con Spark rendono Synapse una scelta potenzialmente migliore di SQL Server.
Dal nostro punto di vista non riteniamo però che si debba pensionare Sql Server ed optare sempre e comunque su Synapse per la creazione di un Data Warehouse, perché dipende molto dal contesto di utilizzo. Ci sono degli specifici scenari per i quali Synapse è stato pensato e delle condizioni senza le quali la sua scelta non comporta sostanziali vantaggi, soprattutto in termini di volumi di dati e necessità di analisi. Un suggerimento che riteniamo utile aldilà della piattaforma tecnologica è quello di valutare attentamente la logica (ETL/ELT) di caricamento di un EDWH, come abbiamo visto il paradigma ELT può portare dei benefici in termini di semplificazione e velocità dei processi.